Optimization in SciPy#
Optimization seeks to find the best (optimal) value of some function subject to constraints
\begin{equation} \mathop{\mathsf{minimize}}_x f(x)\ \text{subject to } c(x) \le b \end{equation}
import numpy as np
import scipy.linalg as la
import matplotlib.pyplot as plt
import scipy.optimize as opt
Functions of One Variable#
An easy example is to minimze a quadratic
f = lambda x: x**2 + 1 # a x^T x + 0*x + 1
x = np.linspace(-2,2,500)
plt.plot(x, f(x))
plt.show()
There is a clear minimum at x = 0. You can search for minima using opt.minimize_scalar
sol = opt.minimize_scalar(f)
sol
message:
Optimization terminated successfully;
The returned value satisfies the termination criteria
(using xtol = 1.48e-08 )
success: True
fun: 1.0
x: 9.803862664247969e-09
nit: 36
nfev: 39
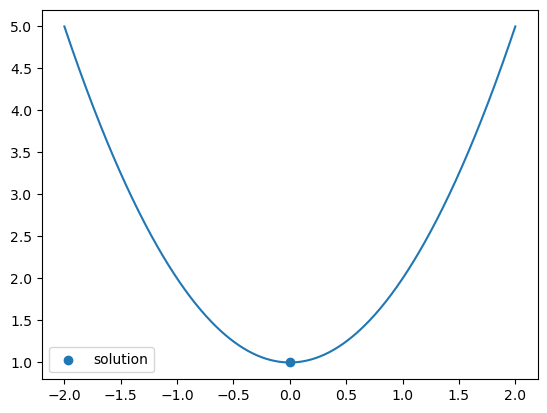
The return type gives you the function value sol.fun, as well as the value of x which achieve the minimum sol.x
x = np.linspace(-2,2,500)
plt.plot(x, f(x))
plt.scatter([sol.x], [sol.fun], label='solution')
plt.legend()
plt.show()
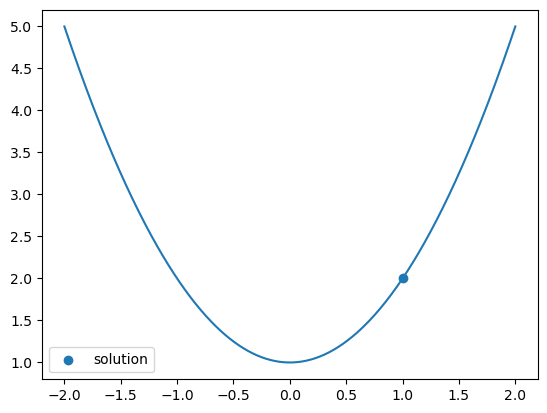
If you want to add constraints such as \(x \ge 1\), you can use bounds, along with specifying the bounded method:
sol = opt.minimize_scalar(f, bounds=(1, 1000), method='bounded')
x = np.linspace(-2,2,500)
plt.plot(x, f(x))
plt.scatter([sol.x], [sol.fun], label='solution')
plt.legend()
plt.show()
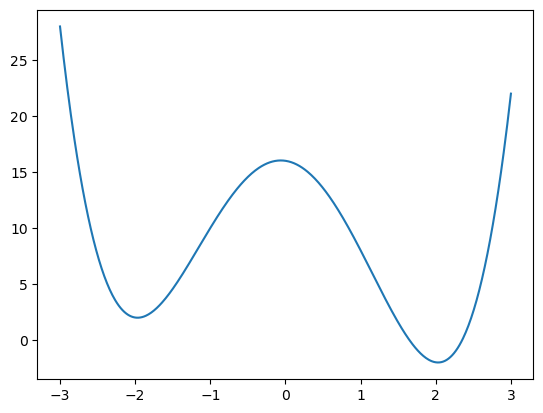
For more complicated functions, there may be multiple solutions
f = lambda x : (x - 2)**2 * (x + 2)**2 - x
x = np.linspace(-3,3,500)
plt.plot(x, f(x))
plt.show()
sol = opt.minimize_scalar(f)
plt.plot(x, f(x))
plt.scatter([sol.x], [sol.fun], label='solution')
plt.legend()
plt.show()
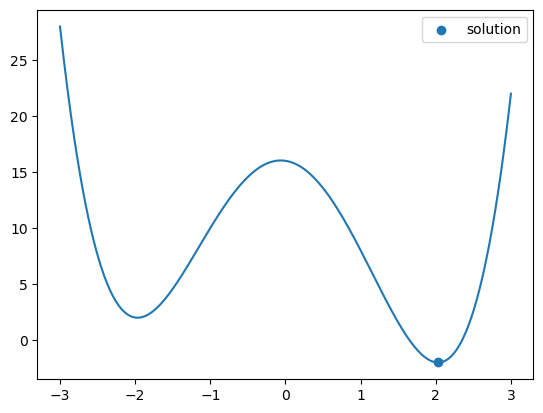
Note that you will only find one minimum, and this minimum will generally only be a local minimum, not a global minimum.
Functions of Multiple variables#
You might also wish to minimize functions of multiple variables. In this case, you use opt.minimize
A multivariate quadratic generally has the form x^T A x + b^T x + c, where x is an n-dimensional vector, A is a n x n matrix, b is a n-dimensional vector, and c is a scalar. When A is positive definite (PD), there is a unique minimum.
n = 2
A = np.random.randn(n+1,n)
A = A.T @ A # generates positive-definite matrix
b = np.random.rand(n)
f = lambda x : np.dot(x - b, A @ (x - b)) # (x - b)^T A (x - b)
sol = opt.minimize(f, np.zeros(n))
sol
message: Optimization terminated successfully.
success: True
status: 0
fun: 3.6140409350212163e-16
x: [ 7.301e-01 2.606e-01]
nit: 5
jac: [-2.377e-15 2.254e-15]
hess_inv: [[ 1.448e-01 -5.021e-03]
[-5.021e-03 1.530e-01]]
nfev: 21
njev: 7
The solution for the above problem is x = b
print(sol.x)
print(b)
print(np.linalg.norm(sol.x - b))
[0.73008137 0.26056669]
[0.73008138 0.26056669]
1.0192650915964426e-08
We can increase the dimension of the problem to be much greater:
n = 100
A = np.random.randn(n+1,n)
A = A.T @ A
b = np.random.rand(n)
f = lambda x : np.dot(x - b, A @ (x - b)) # (x - b)^T A (x - b)
sol = opt.minimize(f, np.zeros(n))
print(la.norm(sol.x - b))
3.5774711959220054e-05
Example: Solving a Linear System#
Recall that solving a linear system means finding \(x\) so that \(A x = b\). We can turn this into an optimization problem by seeking to minimize the residual \(\|b - Ax\|_2\): \begin{equation} \mathop{\mathsf{minimize}}_x |b - Ax|_2\ \end{equation}
n = 5
A = np.random.randn(n,n)
x0 = np.random.randn(n) # ground truth x
b = A @ x0
sol = opt.minimize(lambda x : la.norm(b - A @ x), np.zeros(n))
la.norm(sol.x - x0)
1.6292037522676566e-08
Exercises#
Modify the above example to minimize \(\|b-Ax\|_1\) instead of \(\| b - Ax\|_2\) (look at documentation for
la.norm). Is there any difference in the output ofopt.minimize?How fast is
la.solvecompared to the above example?
## Your code here
Constraints#
Passing in a function to be optimized is fairly straightforward. Constraints are slightly less trivial. These are specified using classes LinearConstraint and NonlinearConstraint
Linear constraints take the form
lb <= A @ x <= ubNonlinear constraints take the form
lb <= fun(x) <= ub
For the special case of a linear constraint with the form lb <= x <= ub, you can use Bounds
Linear Constraints#
Let’s look at how you might implement the linear constraints on a 2-vector x
\begin{equation}
\begin{cases}
-1 \le x_0 \le 1\
c \le A * x \le d
\end{cases}
\end{equation}
where A = np.array([[1,1],[0, 1]], c = -2 * np.ones(2), and d = 2 * np.ones(2)
from scipy.optimize import Bounds, LinearConstraint
# constraint 1
C1 = Bounds(np.array([-1, -np.inf]), np.array([1,np.inf]))
# constraint 2
A = np.array([[1,1],[0,1]])
c = -2 * np.ones(2)
d = 2 * np.ones(2)
C2 = LinearConstraint(A, c, d)
here’s a visualization of the constrained region:
n = 100
xx, yy = np.meshgrid(np.linspace(-3,3,n), np.linspace(-3,3,n))
C = np.zeros((n, n))
for i in range(n):
for j in range(n):
x = np.array([xx[i,j], yy[i,j]])
# constraint 1
c1 = -1 <= xx[i,j] <= 1
# constraint 2
c2 = np.all((c <= A@x, A@x <= d))
C[i,j] = c1 and c2
plt.imshow(C, extent=(-3,3,-3,3), origin='lower')
plt.show()
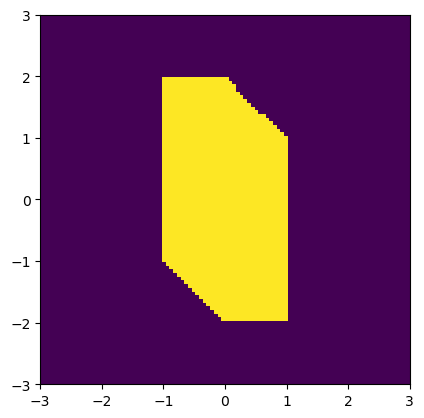
Now, let’s say we want to minimize a function f(x) subject to x obeying the constraints given above. We can simply pass in the constraints
f = lambda x : x[0]*x[1]
sol = opt.minimize(f, np.random.rand(2), bounds=C1, constraints=(C2,))
sol
message: Optimization terminated successfully
success: True
status: 0
fun: -2.000000000005538
x: [ 1.000e+00 -2.000e+00]
nit: 4
jac: [-2.000e+00 1.000e+00]
nfev: 12
njev: 4
Let’s visualize the function in the constrained region:
F = np.zeros((n, n))
for i in range(n):
for j in range(n):
if C[i,j]:
F[i,j] = f([xx[i,j], yy[i,j]])
else:
F[i,j] = np.nan
plt.imshow(F, extent=(-3,3,-3,3), origin='lower')
plt.colorbar()
plt.show()
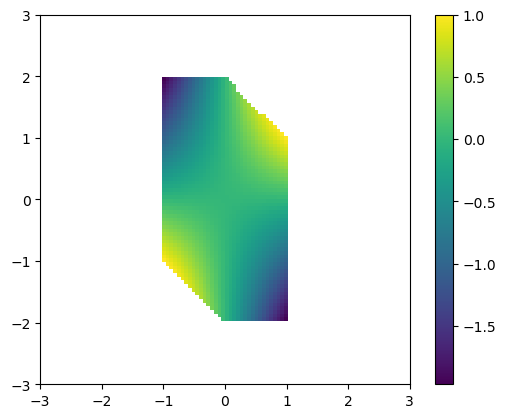
We see that [-1,2] does appear to be a minimum
Nonlinear constraints#
Nonlinear constraints can be used to define more complicated domains. For instance, let’s look at the constraint \begin{equation} 1 \le | x |_2 \le 2 \end{equation}
from scipy.optimize import NonlinearConstraint
C3 = NonlinearConstraint(lambda x : np.linalg.norm(x), 1, 2)
we can visualize this constraint again, and we see that it defines an annulus
n = 100
xx, yy = np.meshgrid(np.linspace(-3,3,n), np.linspace(-3,3,n))
C = np.zeros((n, n))
for i in range(n):
for j in range(n):
x = np.array([xx[i,j], yy[i,j]])
C[i,j] = 1 <= np.linalg.norm(x) <= 2
plt.imshow(C, extent=(-3,3,-3,3), origin='lower')
plt.show()
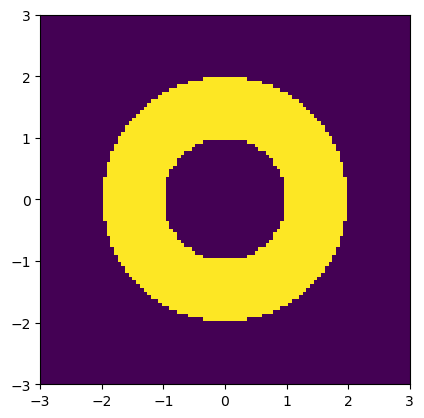
Let’s try minimizing the same function as before: \(f(x) = x[0] * x[1]\)
f = lambda x : x[0]*x[1]
F = np.zeros((n, n))
for i in range(n):
for j in range(n):
if C[i,j]:
F[i,j] = f([xx[i,j], yy[i,j]])
else:
F[i,j] = np.nan
plt.imshow(F, extent=(-3,3,-3,3), origin='lower')
plt.colorbar()
plt.show()
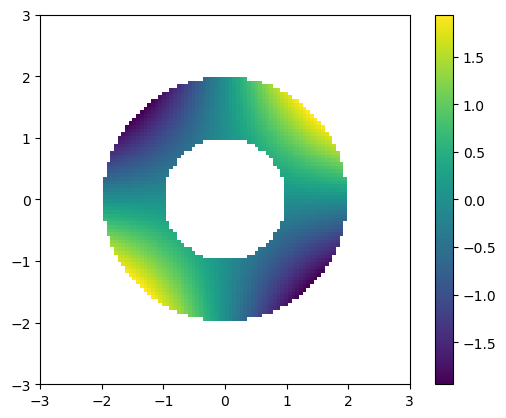
sol = opt.minimize(f, np.random.rand(2), constraints=(C3,))
sol
message: Optimization terminated successfully
success: True
status: 0
fun: -2.0000000005711054
x: [-1.414e+00 1.414e+00]
nit: 12
jac: [ 1.414e+00 -1.414e+00]
nfev: 43
njev: 11
we see that the solution is close to a true minimizer \(x = [-\sqrt{2}, \sqrt{2}]\)
Example: Eigenvalues and Eigenvectors#
One example of an optimzation problem is to find the largest eigenvalue/eigenvector pair of a matrix \(A\). If \(A\) is symmetric, and \((\lambda, x)\) is the largest eigenvalue pair, then \(x\) satisfies \begin{equation} \mathop{\mathsf{minimize}}_x -x^T A x\ \text{subject to } |x|_2 = 1 \end{equation}
And we have \(x^T A x = \lambda\). Let’s try encoding this as an optimization problem.
n = 5
A = np.random.randn(n,n)
A = A + A.T # make symmetric
NormConst = NonlinearConstraint(lambda x : np.linalg.norm(x), 1, 1) # norm constraint
sol = opt.minimize(lambda x : -np.dot(x, A @ x), np.random.randn(5), constraints=(NormConst, ))
sol
message: Optimization terminated successfully
success: True
status: 0
fun: -5.298355703915112
x: [ 2.686e-01 2.067e-01 -3.055e-01 4.153e-01 -7.870e-01]
nit: 57
jac: [-2.848e+00 -2.191e+00 3.235e+00 -4.407e+00 8.336e+00]
nfev: 371
njev: 57
Let’s take a look at a solution obtained using eigh:
import scipy.linalg as la
lam, V = la.eigh(A)
lam[-1], V[:,-1] # largest eigenpair
(5.2983608517562075,
array([-0.26906152, -0.20651925, 0.30493873, -0.41645572, 0.7864685 ]))
print("error in eigenvalue: {}".format(lam[-1] + sol.fun))
print("error in eigenvector: {}".format(la.norm(-sol.x - V[:,-1])))
error in eigenvalue: 5.14784109562072e-06
error in eigenvector: 0.0014240320131961124
Optimization Options#
So far, we haven’t worried too much about the internals of opt.minimize. However, for large problems, you’re often going to want to choose an appropriate solver, and provide Jacobian and Hessian information if you are able to.
A list of available solvers is available in the minimize documentation.
Jacobian#
The Jacobian of a multi-valued function \(f: \mathbb{R}^n \to \mathbb{R}^m\) is the \(m\times n\) matrix \(J_f\), where \begin{equation} J_f[i,j] = \frac{\partial{f}_i}{\partial{x_j}} \end{equation}
If \(f\) is scalar-valued (i.e. \(m = 1\)), then the Jacobian is the transpose of the gradient \(J_f = (\nabla f)^T\)
In our examples so far, we only provided the function. If you are able to provide the Jacobian as well, then you can typically solve problems with fewer function evaluations because you have better information about how to decrease the function value. If you don’t provide the Jacobian, many solvers will try to approximate the Jacobian using finite difference approximations, but these are typically less accurate (and slower) than if you can give an explicit formula.
Note that you can also provide a Jacobian to NonlinearConstraint
# function definition
def f(x):
return np.cos(x[0]) + np.sin(x[1])
# Jacobian of function
def Jf(x):
return np.array([-np.sin(x[0]), np.cos(x[1])])
x0 = np.random.rand(2)
%time sol1 = opt.minimize(f, x0)
sol1
CPU times: user 3.9 ms, sys: 316 µs, total: 4.22 ms
Wall time: 3.92 ms
message: Optimization terminated successfully.
success: True
status: 0
fun: -1.9999999999930531
x: [ 3.142e+00 -1.571e+00]
nit: 9
jac: [-3.010e-06 2.176e-06]
hess_inv: [[ 1.022e+00 -3.197e-05]
[-3.197e-05 1.001e+00]]
nfev: 45
njev: 15
%time sol2 = opt.minimize(f, x0, jac=Jf)
sol2
CPU times: user 0 ns, sys: 3.34 ms, total: 3.34 ms
Wall time: 3.03 ms
message: Optimization terminated successfully.
success: True
status: 0
fun: -1.9999999999931064
x: [ 3.142e+00 -1.571e+00]
nit: 9
jac: [-3.007e-06 2.179e-06]
hess_inv: [[ 1.022e+00 -3.203e-05]
[-3.203e-05 1.001e+00]]
nfev: 15
njev: 15
We see that when we provoide the Jacobian, the number of function evaluations nfev decreases.
Hessian#
The Hessian of a multivariate function \(f: \mathbb{R}^n \to \mathbb{R}\) is a \(n\times n\) matrix \(H_f\) of second derivatives: \begin{equation} H[i,j] = \frac{\partial^2 f}{\partial x_i \partial x_j} \end{equation}
The Hessian provides information about the curvature of the function \(f\), which can be used to accelerate convergence of the optimization algorithm. If you don’t provide the Hessian, many solvers will numerically approximate it, which will typically not work as well as an explicit Hessian.
Again, you can also provide a Hessian to NonlinearConstraint
def Hf(x):
return np.array([[-np.cos(x[0]), 0], [0, -np.sin(x[1])]])
%time sol3 = opt.minimize(f, x0, jac=Jf, hess=Hf)
sol3
CPU times: user 0 ns, sys: 2.99 ms, total: 2.99 ms
Wall time: 4.19 ms
/home/goodwill/miniconda3/envs/pycourse_test/lib/python3.11/site-packages/scipy/optimize/_minimize.py:565: RuntimeWarning: Method BFGS does not use Hessian information (hess).
warn('Method %s does not use Hessian information (hess).' % method,
message: Optimization terminated successfully.
success: True
status: 0
fun: -1.9999999999931064
x: [ 3.142e+00 -1.571e+00]
nit: 9
jac: [-3.007e-06 2.179e-06]
hess_inv: [[ 1.022e+00 -3.203e-05]
[-3.203e-05 1.001e+00]]
nfev: 15
njev: 15
We see that the defualt method BFGS does not use the Hessian. Let’s choose one that does, like Newton-CG.
def Hf(x):
return np.array([[-np.cos(x[0]), 0], [0, -np.sin(x[1])]])
%time sol3 = opt.minimize(f, x0, jac=Jf, hess=Hf, method='Newton-CG')
sol3
CPU times: user 3.35 ms, sys: 0 ns, total: 3.35 ms
Wall time: 3.05 ms
message: Optimization terminated successfully.
success: True
status: 0
fun: -2.0
x: [ 3.142e+00 -1.571e+00]
nit: 6
jac: [ 8.095e-10 8.386e-10]
nfev: 11
njev: 11
nhev: 6
(sol3.x - sol2.x)/np.pi
array([ 9.57261136e-07, -6.93316609e-07])
As we see above, we only compute the function, Jacobian and Hessian for 5 iterations. The wall time is about 5x as fast as when we didn’t provide any of this additional information as well. This will matter more for larger problems.
Solvers#
Here’s a guide to a couple of different solvers. See the notes section of minimize for additional details.
Unconstrained minimization:
BFGS- uses Jacobian evaluations to get a low-rank approximation to the Hessian.Bound constrained minimization:
L-BFGS-B- Variation of BFGS which uses limited memory (theL). Use with very large problems. Only uses Jacobian (not Hessian).Unconstrained minimization with Jacobian/Hessian:
Newton-CG- uses Jacobian and Hessian to exactly solve quadratic approximations to the objective.General constrained minimization:
trust-const- a trust region method for constrained optimization problems. Can use the Hessian of both the objective and constraints.
You can find a lot of information and examples about these different options in the scipy.optimize tutorial
Global Optimization#
opt.minimize is good for finding local minima of functions. This often works well when you have a single minimum, or if you don’t care too much about finding the global minimum.
What if your function has many local minima, but you want to find the global minimum? You can use one of the global optimization functions.
Note that finding a global minumum is generally a much more difficult problem than finding a local minimum, and these functions are not guranteed to find the true global minimum, and may not be very fast.
Here’s an example of a function which has a global minimum, but many local minima:
# global minimum at (pi, -pi/2)
def f(x, a=0.1):
return np.cos(x[0]) + np.sin(x[1]) + a*(x[0] - np.pi)**2 + a*(x[1] + np.pi/2)**2
f([np.pi, -np.pi/2])
-2.0
we can use the basinhopping solver to look for this minimum
sol = opt.basinhopping(f, 10*np.random.rand(2))
# sol = opt.basinhopping(f, np.array([np.pi, -np.pi/2]) + 0.2*np.random.randn(2))
sol
message: ['requested number of basinhopping iterations completed successfully']
success: True
fun: -1.9999999999999987
x: [ 3.142e+00 -1.571e+00]
nit: 100
minimization_failures: 0
nfev: 1254
njev: 418
lowest_optimization_result: message: Optimization terminated successfully.
success: True
status: 0
fun: -1.9999999999999987
x: [ 3.142e+00 -1.571e+00]
nit: 3
jac: [ 5.960e-08 4.470e-08]
hess_inv: [[ 1.000e+00 -2.729e-03]
[-2.729e-03 8.336e-01]]
nfev: 12
njev: 4
as we see, we find a local minimum, but not the global minimum. We can increase the number of basin-hopping iterations, and increase the “temperature” T, which governs the hop size to be the approximate distance between local minima.
%time sol = opt.basinhopping(f, 10*np.random.rand(2), T=1e-6, niter=1)
sol
CPU times: user 0 ns, sys: 7.12 ms, total: 7.12 ms
Wall time: 6.41 ms
message: ['requested number of basinhopping iterations completed successfully']
success: True
fun: -1.99999999999956
x: [ 3.142e+00 -1.571e+00]
nit: 1
minimization_failures: 0
nfev: 42
njev: 14
lowest_optimization_result: message: Optimization terminated successfully.
success: True
status: 0
fun: -1.99999999999956
x: [ 3.142e+00 -1.571e+00]
nit: 3
jac: [ 5.066e-07 9.090e-07]
hess_inv: [[ 8.944e-01 8.015e-02]
[ 8.015e-02 9.392e-01]]
nfev: 12
njev: 4
Now, we get the true minimization value.
Here’s the same problem using opt.dual_annealing:
%time sol = opt.dual_annealing(f, bounds=[[-100,100], [-100,100]])
sol
CPU times: user 132 ms, sys: 5.94 ms, total: 138 ms
Wall time: 138 ms
message: ['Maximum number of iteration reached']
success: True
status: 0
fun: -1.9999999999998104
x: [ 3.142e+00 -1.571e+00]
nit: 1000
nfev: 4037
njev: 12
nhev: 0
This runs much faster, and doesn’t need as much tweaking of the arguments. However, we had to specify bounds in which we would look for the solution.
Finding Roots#
A root of a function \(f: \mathbb{R}^m \to \mathbb{R}^n\) is a point \(x\) so that \(f(x) = 0\). The go-to function for this is opt.root
def f(x):
return x + 2*np.cos(x)
sol = opt.root(f, np.random.rand())
print(sol.x, sol.fun) # root and value
[-1.02986653] [0.]
for scalar functions, you can also use root_scalar
sol = opt.root_scalar(f, x0=-1, x1=1)
sol.root
-1.0298665293222544
You can also find roots of multi-valued functions. E.g. if we want to solve the nonlinear system \begin{equation} x_0 \cos(x_1) = 4\ x_0 x_1 - x_1 = 5 \end{equation}
we can seek to find a root \begin{equation} x_0 \cos(x_1) - 4 = 0\ x_0 x_1 - x_1 - 5 = 0 \end{equation}
def f(x):
return [x[0] * np.cos(x[1]) - 4, x[1]*x[0] - x[1] - 5]
%time sol = opt.root(f, np.ones(2))
sol
CPU times: user 139 µs, sys: 0 ns, total: 139 µs
Wall time: 134 µs
message: The solution converged.
success: True
status: 1
fun: [ 3.732e-12 1.617e-11]
x: [ 6.504e+00 9.084e-01]
nfev: 17
fjac: [[-5.625e-01 -8.268e-01]
[ 8.268e-01 -5.625e-01]]
r: [-1.091e+00 -1.762e+00 -7.374e+00]
qtf: [ 6.257e-08 2.401e-08]
print(sol.x, sol.fun) # root and value
[6.50409711 0.90841421] [3.73212572e-12 1.61710645e-11]
You can also specify the Jacobian for faster convergence (in this case, the Jacobian is \(2 \times 2\))
# returns the function and Jacobian as tuple
def f2(x):
f = [x[0] * np.cos(x[1]) - 4,
x[1]*x[0] - x[1] - 5]
df = np.array([[np.cos(x[1]), -x[0] * np.sin(x[1])],
[x[1], x[0] - 1]])
return f, df
%time sol = opt.root(f2, np.ones(2), jac=True, method='lm')
sol
CPU times: user 898 µs, sys: 78 µs, total: 976 µs
Wall time: 2.4 ms
message: The relative error between two consecutive iterates is at most 0.000000
success: True
status: 2
fun: [ 0.000e+00 0.000e+00]
x: [ 6.504e+00 9.084e-01]
cov_x: [[ 8.747e-01 -2.853e-02]
[-2.853e-02 1.860e-02]]
nfev: 8
njev: 7
fjac: [[ 7.523e+00 -7.316e-01]
[ 2.454e-01 -1.069e+00]]
ipvt: [2 1]
qtf: [ 9.538e-13 1.207e-13]
print(sol.x, sol.fun) # root and value
[6.50409711 0.90841421] [0. 0.]
We see that the computed root in this case satisfies the equations more precisely.
Exercise#
Compute a root of the above example using opt.minimize instead of opt.root. One way to do this is to minimize \(\|f(x)\|\). Do the results differ if you use a 1-norm vs a 2-norm?
Above examples: find roots of multi-valued functions. E.g. if we want to solve the nonlinear system
\begin{equation}
x_0 \cos(x_1) = 4
\end{equation}
\begin{equation}
x_0 x_1 - x_1 = 5
\end{equation}
## 2-norm:
def f(x):
return la.norm([x[0] * np.cos(x[1]) - 4, x[1]*x[0] - x[1] - 5], ord = 2)
sol1 = opt.minimize(f, np.ones(2))
print(sol1.x)
## 1-norm:
def g(x):
return la.norm([x[0] * np.cos(x[1]) - 4, x[1]*x[0] - x[1] - 5], ord =1)
sol2 = opt.minimize(g, np.ones(2))
print(sol2.x)
[6.50409711 0.9084142 ]
[6.38657705 0.89398092]
As we can see from the result, 1-norm result and 2-norm result are slightly different. But they are both very close to the result computated by opt.root.